'x86 Architecture'에 해당되는 글 7건
- 2013.11.08 SMP(Symmetric Multi-Processing) vs. AMP(Asymmetric Multi-Processing)
- 2013.10.28 Memory Segmentation II
- 2013.10.08 Memory Segmentation I
- 2013.10.05 x86 아키텍쳐 메모리 관리 스킴의 이해 II
- 2013.10.03 x86 아키텍쳐 메모리 관리 스킴의 이해 I 4
- 2009.02.04 Assembly에서 Memory To Memory 연산이 불가능한 이유 1
- 2009.01.04 COMPUTER ARCHITECTURE(PART1-OUTLINE)
SMP(Symmetric Multi-Processing) vs. AMP(Asymmetric Multi-Processing)
오늘은 SMP와 AMP에 대해 간략히 학습하는 시간을 갖도록 하겠습니다.
1. SMP(Symmetric Multi-Processing)
SMP은 두 개 이상의 동일한 프로세서가 하나의 메모리, I/O 디바이스, 인터럽트 등의 자원을 공유하여 단일 시스템 버스를 통해, 각각의 프로세서는 다른 프로그램를 실행하고 다른 데이터를 처리하는 시스템을 의미합니다. 달리 얘기하면, 두 개 이상의 프로세서가 하나의 컴퓨터 시스템 아키텍쳐를 공유하도록 연결되어 있으며, 각각의 프로세서는 독립적으로 자신의 작업을 처리한다는 의미가 됩니다. 아래의 그림에서 SMP 시스템을 봅시다.

그래서 SMP는 두 개 이상의 프로세서가 하나의 메인 메모리와 버스를 공유하도록 설계된 하드웨어와 이를 운용하기 위한 소프트웨어 아키텍쳐와 관련이 있습니다. 두 개 이상의 프로세서는 동일한 버스 아키텍쳐를 통해 시스템의 모든 I/O 디바이스에 대한 접근이 가능하며, 이는 적절한 운영체제 정책 디자인(프로세스 스케줄링과 인터럽트 로드 밸런싱 등)에 따라서 운용되어야 합니다. SMP에서 모든 프로세서들은 동일한 기능과 역할을 가지고 작업을 수행합니다. 이를 테면, 모든 프로세서는 운영체제 코드를 실행하고 I/O 오퍼레이션을 담당할 수 있습니다. 오늘날의 대부분의 멀티프로세서 시스템은 SMP 아키텍쳐를 사용합니다. Intel x86 역시 마찬가지로 SMP 아키텍쳐를 채택하고 있습니다. 일반적으로 SMP 시스템 기반에서 보다 빠른 메모리 맵 데이터 엑세스와 시스템 버스 트래픽을 최소화하기 위해, 각각의 프로세서마다 캐쉬 메모리를 가지고 있습니다.
2. AMP(Asymmetric Multi-Processing)
AMP는 두 개 이상의 각각의 프로세서가 자신만의 다른 특정 기능을 수행하는 아키텍쳐를 의미합니다. 예를 들어, 하나의 프로세서가 메인 운영체제를 실행하도록 하고 다른 프로세서는 I/O 오퍼레이션 기능을 전용으로 수행하는 형태의 아키텍쳐로 존재할 수 있습니다. 이때, 두 개의 프로세서는 메인 메모리에서 자신의 커널 이미지를 실행하고 주소 공간 역시 분리되어 있는 컨셉이라고 볼 수 있지요. 여기서 커널 이미지는 동일하거나 서로 다른 것으로 사용될 수 있습니다.
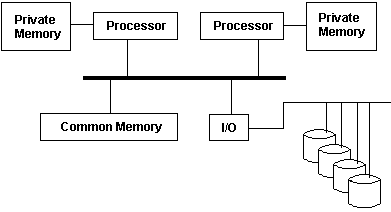
[Asymmetric Multiprocessing Example I]
This configuration has multiple memory units with some of those not shared by all processors
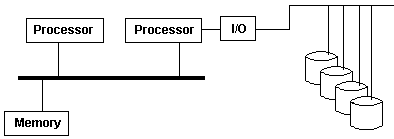
[Asymmetric Multiprocessing Example II]
This configuration has one processor doing all I/O.
3. Summary AMP vs. SMP
An AMP system:
• multiple CPUs
• each of which may be a different architecture [but can be the same]
• each has its own address space
• each may or may not run an OS [and the OSes need not be the same]
• some kind of communication facility between the CPUs is provided
An SMP system:
• multiple CPUs
• each of which has the same architecture
• CPUs share memory space [or, at least, some of it]
• normally an OS is used and this is a single instance that runs on all the CPUs,
dividing work between them
• some kind of communication facility between the CPUs is provided
[and this is normally shared memory]
[Notes and References]
http://en.wikipedia.org/wiki/Symmetric_multiprocessing
http://en.wikipedia.org/wiki/Asymmetric_multiprocessing
http://ohlandl.ipv7.net/CPU/ASMP_SMP.html
http://blogs.mentor.com/colinwalls/blog/2010/06/07/amp-vs-smp/
오늘은 여기까지만 간단히 마무리하겠습니다. 좋은 하루 보내세요.
Written by Simhyeon, Choe
지난 시간에 이어, x86 메모리 관리 스킴에서 나오는 중요한 용어들을 정리해 봅시다.
1) 세그먼트 레지스터(Segment Register)
인텔 문서에서 설명한 내용을 그대로 번역해보면, 어드레스 변환과 코딩 복잡도를 최소화하기 위해, 프로세서가 최대 6개의 세그먼트 셀렉터 값을 유지하기 위한 레지스터 셋(CS, DS, ES, FS, GS, SS)이라고 나와 있습니다. 세그먼트 레지스터와 세그먼트 유닛(세그먼테이션을 처리해주는 하드웨어)이 존재하기 때문에 우리는 특정 세그먼트 영역의 참조를 위해 어떤 범용 레지스터나 스택 영역에 참조할 세그먼트 셀렉터 값을 가져와서 어드레스 변환 작업을 일일이 직접 구현할 필요가 없습니다.

모든 세그먼트 레지스터는 Visible 영역과 Hidden 영역을 가지고 있습니다. 사실, 유저 관점에서는 Visible 영역에 대해서만 관심을 가져도 문제가 없습니다. 유저 관점에서 접근 가능한 레지스터 영역은 오로지 16비트 셀렉터를 저장하기 위한 영역만 존재합니다. Hidden 영역에 대해서 간단히 설명을 드리자면, 이것은 프로세서가 디스크립터를 미리 캐쉬하기 위한 영역으로 사용됩니다. 인텔 메뉴얼(System Programming Guide Vol.3-11)에 언급되어 있듯이, 세그먼트 디스크립터로부터 베이스 어드레스와 리미트 어드레스 읽기 위해, 여분의 버스 사이클 레이턴시없이 프로세서가 바로 어드레스 변환할 수 있습니다.
2) 세그먼트 셀렉터(Segment Selector)와 세그먼트 디스크립터(Segment Descriptor)
세그먼트 셀렉터는 하나의 세그먼트 디스크립터를 지시하기 위한 16비트 구조체입니다. 이 16비트 구조체는 아래와 같은 필드 구조체로 이루어져 있습니다.

여기서 용어 정리를 확실히 짚고 넘어가야 할 부분이 있습니다만, 세그먼트 레지스터를 세그먼트 셀렉터와 동일한 것처럼 이해하실 수 있습니다. 사실 엄밀히 말하면 세그먼트 레지스터와 세그먼트 셀렉터는 같다고 정의할 수 없습니다. 세그먼트 셀렉터는 위에서 말씀드린 것처럼, 세그먼트의 정보가지고 있는 디스크립터를 식별하기 위한 값이며, 세그먼트 레지스터는 실제 물리적인 레지스터입니다. 다만, 주요 커널 관련 서적에서 이를 동일하게 취급하는 이유가 보호 모드에서는 세그먼트 레지스터가 항상 세그먼트 셀렉터 값을 저장하기 위한 용도로 사용되기 때문입니다.
그렇다면 세그먼트 셀렉터가 필요한 이유가 무엇일까요? 이유는 간단합니다. 세그먼트 셀럭터 값을 저장하기 위한 세그먼트 레지스터는 16비트 레지스터 셋인데, 보호 모드에서 모든 세그먼트는 32비트 선형 주소 공간에서 위치할 수 있습니다. 그리고 한 세그먼트 영역의 시작과 끝에 대한 주소 정보도 필요할 것이고 또한 각각의 세그먼트는 서로 다른 보호 속성을 가질 수 있습니다. 유저 레벨에서 접근이 가능한 세그먼트 영역인지 아니면 오로지 커널 레벨에서만 접근이 가능한 영역인지 혹은 오직 읽기만 가능한 영역이 있는가하면, 읽기/쓰기 모두 허용하는 등의 속성들을 의미합니다. 16비트 세그먼트 레지스터로 32비트 선형 주소 공간을 모두 표현할 수 없을 뿐만 아니라, 그런 속성 정보들 역시 표현할 수가 없습니다. 이 때문에 각 세그먼트마다 여러가지 속성 정보를 가지고 있는 별도의 구조체가 필요합니다만, 그것이 세그먼트 디스크립터(Segment Descriptor)입니다. 이 구조체의 크기는 총 64비트로 구성되어 있으며, 아래와 같이 주소 정보 및 여러가지 속성 필드들로 구성되어 있습니다.

그렇다면 이번에는 16비트 세그먼트 레지스터에 64비트 세그먼트 디스크립터 정보를 담을 수 있을까요? 역시 불가능합니다만, 이쯤되면 다들 아시겠지요. 바로 하나의 세그먼트 디스크립터를 가리키기 위한 용도로 16비트 세그먼트 셀렉터 값을 참조한다는 사실을 말입니다. 16비트 세그먼트 셀렉터 정보를 보면 세그먼트 디스크립터의 인덱스 값을 가지고 있습니다. 그 인덱스 값으로 특정 세그먼트 디스크립터를 찾아갈 수가 있지요.
3) 세그먼트 디스크립터 테이블(Segment Descriptor Table)
이것은 두 개 이상 세그먼트 디스크립터들의 집합입니다. 방금전에 제가 세그먼트 디스크립터는 여러가지 속성 필드를 가지고 있는 구조체라고 언급드렸습니다. 그런 구조체를 연속적으로 여러 개를 가지고 있는 구조체 배열이 세그먼트 디스크립터 테이블입니다.

4) 주소 개념 설명
- 논리적인 주소(Logical Address)
세그먼트 + 오프셋(DS:[0x1000]) 조합으로 표현된 주소를 의미합니다.
- 선형 주소(Linear Address)
세그먼트 + 오프셋 조합의 논리적인 주소로 세그먼테이션을 통해, 특정 세그먼트 디스크립터의 베이스 주소와 오프셋을 합친 주소값입니다.
- 물리 주소(Physical Address)
실제 물리 메모리 주소를 의미합니다.
- 가상 주소(Virtual Address)
페이징 스킴을 지원할 때 선형 주소가 가상 주소가 됩니다.
보호 모드에서 선형 주소는 페이징 스킴의 지원 여부에 따라 개념이 물리 주소를 의미하거나 가상 주소를 의미할 수 있습니다. 아래의 표를 참조하시면 쉽게 구분할 수 있습니다.

여기까지 마무리하고 다음 시간에는 세그먼트 관련 속성 필드에 대해 알아보도록 하겠습니다.
좋은 밤 보내세요.
Written by Simhyeon, Choe
지난 시간에 이어 메모리 세그먼테이션에 대해서 자세히 알아봅시다.
세그먼테이션은 x86 아키텍쳐에서 제공하는 메모리 관리 스킴 중에 하나로써, 메인 메모리 영역을 세그먼트라는 단위로 분할하여 관리합니다. 세그먼테이션을 수행한다는 의미는 하나의 세그먼트 영역의 베이스 어드레스와 오프셋으로 어떤 특정 메모리 위치를 참조하는 동작을 의미합니다. 이런 뻔한 설명을 드려도 세그먼테이션 개념이 와닿지 않는 핵심적인 의문 두가지가 있습니다. 세그먼테이션을 수행하는 주체는 무엇인가? 그리고 세그먼테이션은 언제 수행되는가? 우선 우리는 이 질문에 대답을 해보도록 합시다.
아래의 간단한 C언어 코드로 예를 들겠습니다.
unsigned int gValue; // 데이터 세그먼트 오프셋 0x1000에 전역 변수 gValue가 위치한다고 가정
int main(void)
{
gValue = 0x0000FFFF; // 0x0000FFFF 값을 전역 변수 gValue에 대입
return 0;
}
자, 이번에는 위의 C언어 코드를 CPU가 해석할 수 있도록 컴파일해서 저 간단한 프로그램을 실행했다고 가정하겠습니다. (사실, 의미없는 동작이기 때문에 컴파일러가 이를 최적화하지만 그냥 무시합시다)
그러면 메모리에 로딩된 프로그램은 대략적으로 아래의 어셈블리 코드로 동작할 것입니다.
0x4005000 MOV EAX, 0x0000FFFF
0x4005004 MOV DWORD PTR DS:[0x1000], EAX
1) 프로그램 카운터 0x4005000에서 명령어 MOV EAX, 0x0000FFFF을 패치하고 수행
- EAX 레지스터에 즉치값 0x0000FFFF 대입
2) 프로그램 카운터 0x4005004에서 명령어 MOV DWORD PTR DS:[0x1000], EAX를 패치하고 수행
- 데이터 세그먼트 베이스 어드레스로부터 오프셋 0x1000 위치에서 4바이트만큼 참조하여
0x0000FFFF을 쓰기

[그림1] CPU가 명령어를 실행할 때, 오퍼랜드에 기술된 메모리 위치를 참조하는 과정
세그먼테이션 동작을 전적으로 수행하는 주체는 CPU가 되고, 세그먼테이션을 수행하는 시점은 CPU가 하나의 명령어를 패치, 디코딩 후 오퍼랜드의 주소를 지정하기 위해 계산하는 시점입니다. 이때, 명령어 셋에 명시된 어드레싱 모드가 Immediate Addressing이 아닌 Direct Addressing, Register Indirect Addressing, 그리고 Base Addressing 등에 해당한다면 보호 모드(Protected Mode)에서는 세그먼트 어드레싱(Segmented Addressing) 즉, 세그먼테이션을 수행하게 됩니다. 여기선 세그먼테이션을 수행하는 시점을 알게 되었습니다만, 그 구체적인 과정에 대해서는 여전히 언급하지 않았습니다. 다음에는 위의 그림에 나오는 세그먼테이션 과정을 설명하기 앞서, 몇 가지 이해가 필요한 개념들의 정의를 짚고 넘어 가도록 합시다.
Notes and References
------------------------------------------------------------------------------------------------------
1. http://cs.smith.edu/~thiebaut/ArtOfAssembly/CH03/CH03-3.html (Instruction Execution)
2. http://en.wikipedia.org/wiki/X86#Addressing_modes (Addressing Modes)
3. http://forum.osdev.org/viewtopic.php?f=11&t=26012&start=0 (To load a segment register, CPU operation)
4. http://www.supernovah.com/Tutorials/Assembly3.php (Addressing Modes)
5. IA-32 Intel Architecture Manual VOLUME 2A: Instruction Set Reference, A-M (Instruction Set Architecture)
------------------------------------------------------------------------------------------------------
오늘은 시간이 늦었으니, 짧게 마무리하고 여기서 다시 추가로 계속 설명드리도록 하겠습니다.
편안한 밤 보내세요.
Written by Simhyeon, Choe
지난 시간에 이어, x86 아키텍쳐 메모리 관리 스킴에 대해서 계속 공부하도록 합시다. 지난 시간에는 세그먼테이션과 페이징의 기본 개념과 필요성에 대해서 언급하였는데요. 현재의 메모리 관리 스킴을 설명하기 앞서, 일단 과거 x86 아키텍쳐의 메모리 관리 스킴의 히스토리를 조금 짚고 넘어가도록 하겠습니다.
1) 세그먼트(Segment)와 오프셋(Offset)
세그먼테이션은 고유한 속성을 가진 메모리의 조각을 영역별로 나누어 어드레싱하고 관리하는 기법이라고 이전 챕터에서 정의하였습니다. 과거 8086 아키텍쳐에서 지원하는 세그먼테이션의 경우에는 현재 세그먼테이션 스킴과 비교해 컨셉이 전혀 달랐습니다. 8086 아키텍쳐에서 사용한 세그먼테이션의 근본적인 배경은 더 많은 메모리 주소 공간을 어드레싱하기 위함이었지요. 당시 8086 아키텍쳐는 8개의 16비트 레지스터와 16비트 데이터 버스와 20비트 어드레스 버스를 가졌습니다. 하나의 16비트 레지스터로 20비트 어드레스를 표현할 수 없었기 때문에 인텔이 고안해낸 방법은 세그먼트:오프셋 조합으로 20비트 어드레스를 나타내는 것이었습니다. 그러니까 세그먼트 값을 4비트만큼 왼쪽으로 쉬프트하고 여기에 오프셋 값을 더하여 온전한 20비트의 물리 주소를 표현하였습니다.

이와 같이, 세그먼트:오프셋 조합으로 물리 주소를 표현하면 동일한 물리 주소를 다양한 세그먼트:오프셋 조합으로 표현할 수 있습니다. (예를 들면, 0xFFFFF 물리 주소는 FFFFh:000Fh, FFF0h:00FFh, FF00h:0FFFh, F000h:FFFFh로 표현 가능) 그렇다면 만약에 FFFFh:0010h으로 물리 주소를 표현하면 어떻게 될까요? 이 경우엔 20비트로 표현할 수 있는 범위를 초과하기 때문에 다시 0x0000의 물리 주소로 랩핑됩니다.
2) 리얼 모드(Real Mode or Real Address Mode)와 보호 모드(Protected Mode)
8086 머신에서는 20비트 어드레스를 표현하기 위해 세그먼트:오프셋 조합으로 주소 지정을 하게 되는데, 1MB 범위의 메모리 영역 어느 곳이든 주소 지정이 가능할 뿐만아니라, 읽기/쓰기가 가능합니다. 즉, 전적으로 프로그램을 구현하는 프로그래머가 메모리 관리를 책임져야 하며, 이는 과거 머신에서 메모리 관리에 대한 안정성과 보안성에 대한 고려가 되지 않았습니다. 이러한 CPU 연산 모드를 리얼 모드라고 합니다. 8086 이후에 등장하게 된 80286 프로세서부터 멀티 태스킹 환경을 제공했습니다. 그리고 어드레스 버스가 24비트로 확장되었으며, 더이상 이전의 세그먼트:오프셋 조합으로 주소 지정하지 않고 세그먼트 셀렉터가 가리키는 세그먼트 디스크립터의 베이스 어드레스와 오프셋의 조합으로 최대 16MB까지 주소 지정을 가능하도록 하였습니다. 이것은 제가 원래 처음에 설명드렸던 세그먼테이션 컨셉이기도 합니다. 하위 호환성 유지를 위해 여전히 리얼 모드를 제공하였고 새롭게 보호 모드를 도입하였습니다. 이것은 다른 세그먼트들간의 코드, 데이터, 스택 영역에 대한 오버랩핑을 제한하도록 하고 세그먼트마다 특권 레벨을 부여하여 합법적이지 않은 접근에 대해 각 세그먼트 영역을 보호하였습니다. 80286 다음으로 등장하게 된 프로세서가 80386으로, 이때부터 완전한 32비트 레지스터 셋과 함께 32비트 버스 라인을 가졌습니다. 여기서부터 유저 영역과 커널 영역의 주소 공간을 나누어 유저 레벨에서 동작하는 프로그램이 커널 영역의 접근을 보호하도록 하였습니다. 그리고 유저 레벨의 프로세스마다 독립적인 영역으로 분리를 통해, 서로간의 메모리 영역 침범을 제한하여 안정성과 보안성을 높였습니다. 그리고 페이징 유닛의 추가로, 유저 프로세스마다 4GB에 이르는 주소 공간에 가상 메모리를 할당할 수 있도록 지원하였습니다.
여기까지 정리를 마무리하도록 하겠습니다. 즐거운 하루 보내세요.
Written by Simhyeon, Choe
이번 시간에는 x86 아키텍쳐의 메모리 관리 스킴에 대해서 알아 보도록 합시다.
사실, 이 주제를 포스팅하는 것에 대해 고민하였습니다. 이 주제로 검색하면 굉장히 잘 정리된 블로그나 기술 문서들이 많기 때문입니다. 특히, 운영체제 개발 관련 서적에서는 이와 관련된 내용이 체계적으로 잘 정리가 되어 있습니다. 그리고 그것을 구현한 코드도 함께 볼 수 있구요. 이미 보편적으로 오래전에 파급된 이 주제를 제가 이제와서 언급하는게 적절한지는 잘 모르겠군요. 제가 x86 Architecture에 대해 공부한지는 꽤 되었습니다. 예전에 차라리 정리를 해놓았으면 하는 후회가 남네요. 뒤늦게라도 다시 정리를 해보는 것도 리마인드 차원에서 나쁘지는 않을 것 같군요. 사실 저는 개발하는 것보다 이론 공부를 더 좋아하는 성격인지라, 순전히 이론만으로 이 주제를 잘 설명할지는 의문이긴 합니다만, 이번 시간에 한 번 정리를 해보도록 하겠습니다.
당연히 이 주제는 너무나도 유명한 아래의 인텔 메뉴얼을 참고하였습니다.
Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3A:
System Programming Guide, Part 1
x86 아키텍쳐에서 메모리 관리 기법은 크게 세그먼테이션과 페이징으로 분류할 수 있습니다. 이 두가지 메모리 관리 기법을 언급드리기 앞서, 우리가 선행해야 할 것은 과거의 메모리 관리 스킴입니다. 과거 메모리 관리 스킴으로 시작하여 현재 어떻게 변천해 왔는지 알아보는 것은 충분히 의미가 있습니다.
우선, 세그먼테이션(Segmentation)를 간단히 정의해도록 합시다. 세그먼트는 우리말로 풀어보면 사전적 의미는 '조각'이고, 세그먼테이션은 '분할'로 나오네요. 굳이 억지로 번역하면 '조각 나누기' 정도로 해석할 수 있겠네요. 그럼 필요한 이유가 뭘까요? 저의 생각으로는 적당히 세 가지 정도를 이유로 들 수 있을 것 같은데요. 첫 번째는 코드와 데이터처럼, 서로 다른 성격을 지닌 메모리 영역을 나누어 관리하기 위함입니다. 당연한 얘기가 되겠지만 프로그램을 동작중에 데이터를 코드 영역에다가 쓰기 행위는 제한되어야 할 것이고, 또 다른 예로는 프로그램 특성상 오직 읽어야 하는 영역임에도 불구하고 이를 접근하여 쓰기를 시도하는 행위도 읽기 전용 메모리 속성으로 구분되어야 할 것입니다. 이와 같이, 세그먼테이션을 통해 각 세그먼트의 보호 속성을 지정하여 관리할 수 있습니다. 두 번째는 필요에 따라서 특정 메모리 영역을 공유할 수 있습니다. 동일한 프로그램을 두 번 실행되었다고 하더라도 프로그램 코드를 두 번 메모리에 로딩할 필요없이 특정 코드 세그먼트 영역에 한 번만 로드하여 공유하고 데이터 영역만 분리하여 효율적인 메모리 관리를 할 수 있습니다. 이것은 사실 멀티 태스킹 환경에서 그러한 지원은 당연하다고 볼 수 있지요. 세 번째 이유는 특정 메모리 영역의 접근이 용이하다는 점입니다. 단순히 물리 메모리를 하나로 코드와 데이터 등의 영역을 관리한다면 유저 입장에서는 특정 영역에 접근할 때, 예를 들어 코드는 0xFFFF, 메모리는 0x1000와 같은 절대 위치를 항상 참조해야 하기 때문에 번거로움이 있습니다. 그래서 각 세그먼트 영역마다 베이스 주소와 한계 주소과 같은 정보를 CPU에게 미리 알려 준 상태라면 유저(프로그래머) 관점에서는 어떤 영역이든 오프셋 0을 기준으로 하여 접근하면 되니 메모리 관리에 신경쓰지 않아도 될 것입니다. 다시 요약하면, 속성이 다른 영역의 메모리를 적절히 나누어 관리하기 위한 기법으로 정의할 수 있습니다. 그렇다면 이번에는 페이징에 대한 정의를 찾아봐야 할 것 같습니다만, 앞서 페이징이 필요한 이유부터 알아봅시다.

우선 세그먼테이션을 기반으로 하여 가상 메모리가 아닌 순수 물리 메모리상에서 여러 개의 프로그램이 동작하는 멀티 태스킹 환경이라고 가정하겠습니다. 그림①은 프로그램 크기가 다른 프로세스 A, B, C, D, E가 차례대로 물리 메모리 영역에 로딩된 상황입니다. 순서대로 실행하여 메모리에 로딩한 상황 자체는 특별한 문제가 없습니다. 그리고 그림②에서는 프로세스 B와 D가 실행이 끝나고 언로딩된 상황을 보여주고 있습니다. 여기서 문제는 다시 새로운 프로세스 F를 실행하기 위해 로딩하려는 시점입니다. 그림에서 보시다시피, ⓐ와 ⓑ 영역에 Process F를 연속된 공간으로 로딩하기엔 공간이 부족합니다. 이와 같이, ⓐ와 ⓑ 영역을 메모리에서 외부 단편화(External Fragmentation)가 발생하였다고 표현합니다. 외부 단편화의 범위는 프로세스가 가지고 있는 코드와 데이터 영역 모두가 됩니다. 이런 외부 단편화로 인해, 프로그램 로딩을 위한 적절한 공간을 할당받을 수 없다면 기존에 로딩한 프로그램들을 재배치하고 조각으로 나누어진 영역들을 하나로 합치는 등의 워스트 케이스가 발생하면 그 버든은 아주 클 수 밖에 없지요. 바꿔 얘기하면, 외부 단편화 문제는 세그먼테이션에서 발생하는 문제라고 말씀드릴 수 있습니다. 외부 단편화 문제를 해결하기 위해, 인텔 x86에서는 페이징 기법을 제공합니다. 프로그램을 실행할 때 코드와 데이터를 통째로 로딩하는 것이 아니라, 모든 영역을 페이지 단위(IA-32에서는 기본 4K)로 나누어 메모리를 관리할 수 있습니다.

위의 왼쪽 그림을 보면, 물리 메모리에서 각 프로세스의 코드와 데이터 일부가 페이지 단위로 로드되어 있습니다. 중간 그림에서 프로세스 D의 실행이 종료되고 페이지 아웃된 후에 새로운 프로세스 E 코드 일부가 물리 메모리에 로드된 것을 보여주고 있습니다. 페이지 단위의 메모리 공간 확보만 보장된다면 프로그램 영역 할당은 쉽게 이루어질 수 있습니다. 즉, 페이징 기법으로 외부 단편화 문제를 극복할 수 있습니다. 그리고 여기서 아직 가상 메모리 개념을 자세히 설명드리지 않았습니다만, 사실 페이징 기법은 가상 메모리 스킴과 밀접한 관련이 있습니다. 위의 그림에서는 단지 실행에 필요한 프로세스 코드와 데이터 일부가 로드된 것을 보여준다는 점을 유념하시기 바랍니다. 일단, 오늘은 여기까지만 정리하고 다음편에서 이 주제에 대해서 계속 설명드리겠습니다. 좋은 하루 보내세요.
Written by Simhyeon, Choe
Written By Sim-Hyeon, Choe
연산이 불가능한 이유를 묻는 질문이 있었습니다. 거기에 대한 이유가 명확하지 않았는데요...
나름대로 유추해 보았습니다(결코 정답은 아닙니다).
전용 명령어를 제공해 주고 있습니다. 메모리에 직접 접근하여 하나의 Instruction을 인출하여
읽거나 쓰는 과정 자체는 한 사이클 내에 처리할 수가 없습니다. Indirect Cycle과 같은 Sub
Cycle이 필요하기 때문이지요.
Indirect Addressing mode로 메모리 필드의 내용을 왼쪽으로 이동하라는 명령어입니다.
수 있습니다.
소요가 될 수 있는 오버헤드가 매우 큰 명령어가 되겠군요. 뿐만 아니라, Program Control
Unit 내부에 있는 Control Memory에서 위와 같이 큰 루틴을 저장한다고 하였을 때, 기억
장소 낭비가 상당하지요.
중복 사이클 루틴(2번의 인출 과정)도 함께 포함하여 하나의 루틴으로 구성하여야 하기 때문에
비효율적입니다.
물론 위의 Micro-Operation은 어디까지나 저의 유추이기 때문에 실제로 어느 정도 길이의
Instruction일지 확실하게 장담할 수 없으나, 대략적인 그림은 흡사하다고 생각하고 있습니다.
mov eax, dword ptr [addr]
하지만, 위에서 언급한 것과 같이 Control Memory에서 Sub routine의 크기나 구성면에서
볼 때, 비효율적이라고 할 수 있지요.
저의 컴퓨터(Intel-Pentium Quad core)에서 OpCode를 분석해보면, Instruction Set에서
하나의 간접 비트만 쓰도록 디자인 되어 있습니다(OllyDebug와 Intel-Manual 조합으로 분석
한 결과) 따라서 하나의 Operand 뿐만 아니라, 두 Operand 모두 간접 비트임을 나타낼 수
있는 비트열이 필요합니다. 이것은 단순히 추가적으로 간접 비트를 쓰도록 지원하는 일과 같이
간단할지 의문이네요. Data Bus Line의 길이가 적어도 80Bit이상은 되어야 합니다.
왜냐하면, 저의 프로세서 Data Bus는 64Bit인데요. 두 Operand에 대하여 32Bit 주소 지정
이 가능해야 하기 때문에 최소 64Bit까지 필요합니다. (물론 64Bit 프로세서일 경우에는 이러
한 Instruction Set 지원이 불가능하겠지요)
뿐만 아니라, 프로세서에 내장되어 있는 MBR, IR, IBR 등과 같은 레지스터도 위의 Data Bus
크기를 수용할 수 있는 칩으로 집적해야 되는데, 이것은 곧 프로세서 제조 비용이 상승하게 되
는 문제이기도 하지요.
때문에 지원하지 않는 것이 아니냐는 것이 저의 생각입니다.
COMPUTER ARCHITECTURE(PART1-OUTLINE) Written By Sim-Hyeon, Choe
오늘은 컴퓨터 구조에 대해서 이야기하는 시간을 갖도록 하겠습니다.
우선 역사를 간략하게 알아보도록 합시다.
최초에 등장한 컴퓨터는 다들 아시다시피 ENIAC(Electronic Numerical Integrator And Computer)
입니다. 펜실베니아 대학에서 개발된 ENIAC은 세계 최초의 일반 목적용 전자식 디지털 컴퓨터이며,
세계 2차 대전에서 미사일의 탄도 계산을 목적으로 개발된 컴퓨터입니다.
당시 미국은 미사일을 발사하기 위해 사정거리와 궤도를 직접 일일이 계산해 주어야 하였는데, 이것을
계산하는데에 많은 시간을 소요하기 때문에 이러한 작업을 신속히 처리해 줄 수 있는 기계의 개발을
제안하였습니다(By John Mauchly and Presper Eckert).
마침내 개발된 이 기계는 그 무게가 무려 30톤에 육박하며 크기는 1500 평방 피트를 차지할 만큼
거대하였고 18,000개의 진공관으로 구성되어있는 기계인데, 이것을 조작하기 위해서는 스위치를 일일이
수동으로 조작하여야 했으며, 케이블들을 플러그에 연결하고 빼주어야하는 매우 번거로운 작업을 해야
했습니다. ENIAC은 수많은 진공관들을 기반으로 동작하기 때문에 이 진공관이 나가거나 하는 일이
비일비재하였고 기계의 고장이 매우 잦았다고 합니다. 이 기계를 현대에 와서 평가하자면, 지금의
손바닥 크기만한 계산기보다 못한 크나큰 고철덩어리에 지나지 않겠지요.
여하튼 그렇게 개발된 기계는 위에서 언급하였다시피 조작이 굉장히 번거로운 것이 단점입니다.
여기서 말하는 조작은 어떤 계산의 결과값을 획득하기 위해 수동으로 프로그램하는 작업(프로그래밍)을
말하는데, 당시에는 이 컴퓨터를 조작할 수 있는 관리 기술자 여러 명을 두고 작동시켰다고 하더군요.
항상 계산을 할 때마다 프로그램해주어야 하기 때문에 여간 힘든일이 아닐 수 없지요.
이 ENIAC 개발 프로젝트의 기술 고문이었던 수학자 John Von Neumann은 이러한 단점을 보완하기
위해 프로그램 내장 방식(Program Stored Concept)을 제안(1945)하였습니다.
프로그램 내장 방식은 실행될 프로그램의 데이터와 명령어를 미리 프로그래밍하여 기억 장치에 상주시
키는 방식을 의미합니다. 이렇게 디자인한다면 단지 컴퓨터에서 기억 장치에 있는 데이터와 명령어들을
읽어들여 실행만 시키면 되기 때문에 번거롭게 계산할 때마다 수동으로 프로그램할 필요가 없게 되겠
지요. (사견이지만 폰 노이만이 이러한 방식을 고안하지 않았더라면 아직도 우리는 함께 수많은 스위치
를 올렸다 혹은 내렸다하며 조작하고 있을지도 모르지요. 하하)

이러한 컴퓨터를 폰 노이만 아키텍쳐(Von Neumann Architecture)라고 합니다. 이 구조가 오늘날 우
리의 컴퓨터 구조의 근간이 되고 있으며, 지금의 컴퓨터 구조도 이와 크게 다르지 않습니다.
이후에 컴퓨터는 비약적으로 발전하기 시작하였지요.
일단 여기까지 정리하고 다음에 다시 계속 하도록 하겠습니다.
 Prev
Prev

 Rss Feed
Rss Feed
{kind=link}