'Category'에 해당되는 글 88건
- 2018.06.23 Perfect One Day Project
- 2016.04.11 나에게 들려주는 이야기 4
- 2013.11.09 Setting up Kernel mode debugging over a USB 2.0 Cable manually 1
- 2013.11.08 SMP(Symmetric Multi-Processing) vs. AMP(Asymmetric Multi-Processing)
- 2013.10.28 Memory Segmentation II
- 2013.10.10 Small talk with junior in university
- 2013.10.08 Memory Segmentation I
- 2013.10.05 x86 아키텍쳐 메모리 관리 스킴의 이해 II
- 2013.10.03 x86 아키텍쳐 메모리 관리 스킴의 이해 I 4
- 2013.09.12 Device and Driver Layering I
To learn and to grow up, it gives me a sense of achievement. I have realized the
importance of working on self development constantly. So I formed a campaign
named 'Perfect One Day Project' three weeks ago, which aims to practice productive
activities, such as a study or an exercise. I have recruited fellow members to join this
campaign together. I formed this campaign so that I can make an effort with fellow
members to create good habits. As you know, it's difficult to do productive activities
consistently. Especially, if you try to do it alone, you may give up earlier than you
thought. That's why I recommend that you join this campaign. I'm looking forward
to bringing many positive changes in us. Of course, it doesn't mean we don't have
any rules to follow in this campaign. Let me tell you about the kinds of rules simply.
First of all, if you are able to achieve some productive activities, you should post
what you did on our chatroom on that day. You should post the time of how long it
takes and the kind of activitiy you did in more details. Finally, you should attach
some evidence, such as photos or text that can be used as proof. Once you post
your activity on our chat room, I will feed the statistics information back to you
every friday night. I'm sure that this campaign will really help us to try to do the
productive activities harder.
Written by Simhyeon, Choe
약 7년간 대기업에서 소프트웨어 엔지니어로 회사 생활을 하며 내가 느낀 것은 과연 이 회사
생활이 정말 내가 원했던 것인가하고 나 스스로에게 의문을 던지게 한다.
"심현씨, 이거이거 해주세요. 오늘까지 꼭 해야돼요."
"네..."
그런 업무들이 끊임없다. 내가 아닌 제품을 위한 업무들의 연속이다. 이것이 내가 진정으로
원했던 삶이던가...? 혹자는 말한다. "회사 생활이 다 그렇지 뭐. 대신 돈 많이 받잖아?"
그게 내가 원했던 길이었던가? 그럼 회사 생활 열심히해서 10년 넘게 다니고 수석된 후
수 억대 가량 모은 후에 건물 하나 사면 그게 최고인건가? 무엇을 위해? 나를 위해?
아니면 나 이외의 물질적인 가치와 금전적인 것들을 위해? 그것이 정녕 내가 바랬던 성공이었던가?
출근하고 밤 늦게 퇴근때까지 나는 거의 웃음없이 무표정으로 자리에 앉아서 그들이 원하는 코드를
만들어 주기에 바빴다. 주지 않으면 빨리 해야한다고 끊임없이 재촉하고 압박하는 것을
반복하고 삽질의 시간을 보내면서 그들의 원하는 것을 주면 아무일 없었다는 듯이 그게
그걸로 끝이다. 그러고는 또 다른 요청이 끊임없이 쇄도하고 처리해줘야 하는 무수한 반복의
연속이었다. 나라는 존재는 오로지 제품을 위해서 존재해야 했고 나의 건강, 나의 행복,
나의 삶의 질은 철저히 회사 제품에 의해서 결정되고 있었다. 그렇게 회사 생활 열심히 10년 넘게
다니면 정말 고생하고 장한 회사 생활일지도 모른다. 하지만, 반대로 그 10년은 잃어버린
청춘이 될테지. 혹자는 말한다. "어쩔 수 없어, 그렇게 살아갈 수 밖에 없는거야." 여기서 다시
질문하고 싶다. 그렇게 맹목적인 회사 생활하는 동안 너는 정말 즐거웠냐고. 너는 정말 너의 인생을
살아온거냐고. 수 년 넘게 회사 생활하면서 적어도 한 달 정도는 즐거웠던가? 그 한 달을 위해
수 년 간의 희생은 당연한건가? 그렇게 회사 생활 수석될 때까지 하면 정말 보람있었다고
생각하는 비중이 클까 아니면 후회하는 비중이 클까? 나의 인생은 우주의 수십 억 광년 빛의
속도 시간에서 티끌도 안되는 찰나일 것이기도 하지만 적어도 나에게는 길게 내다봐야 할 인생인데
내가 살고 싶은 삶이 아닌, 남에게 보여지는 삶을 살아가는 것은 너무나도 불쌍한 인생을 살다가
생을 마감할 때 후회하지 않을까? 지금은 나의 월급이 얼마냐, 나의 위치가 어디냐가 중요하지
않아. 지금 중요한 것은 내가 뭘 하고 싶어 하느냐인거지. 내면 어디엔가 웅크리고 있는 나의
잠재력을 다시금 끄집어 내는 것, 그리고 내가 주도하는 삶을 살아가야 하는 것, 바로 그것이
내가 지금 되찾아야 할 것들이지. 도전과 동기 부여는 내 삶의 테두리에서 내가 선택하고 결정한
삶의 안에서 만들어 가야할 부분이야. 나의 안이 아닌, 밖에서 존재하는 도전과 동기 부여는
실제로 내가 만든게 아니라 나 이외의 외압에 의해서 만들어진 허상에 불과하기 때문에
오래가지 않아. 왜냐하면 진정한 나의 안에서 우러나온 도전과 동기 부여가 아니기 때문이지.
나의 삶에는 나에게 선택권이 있고 그 선택에 따른 책임은 나에게 있어. 나는 회사 생활하면서
조금이라도 내가 선택할 수 있는 권한이 있었던가? 아니다.
그저 "네, 네, 네, 알겠습니다."하기 바빴지. 철저히 소모품인 나는 발전없이 제품에 기대어
기약없는 미래를 위해 일을 할 뿐이지. 언제나 조직 변화에 전전긍긍하며 다른 조직원들에 대해
떠들어 대면서 말이지. 그리고 내 자아의 내면 목소리는 철저히 죽인 채, 가식적인 얘기들을
그들앞에 늘어 놓는 것, 그런 직장인의 생활에 나의 미래를 맡긴다는 것은 참으로 측은하고
안타까울 뿐이지 않아?
... ...
그래, 내가 가야할 방향은 이제 좀 더 명확해졌어.
하얀 안개와 구름들 속에 가려져 보이지 않던 막막한 길에 걸어갈 용기가 싹트고 있지.
하지만, 여전히 두려운 것은 사실이야. 그동안 새장에 갖혀 있어서 내가 날개짓을 예전처럼
펼칠 수 있을까하고 두려움이 앞서 솔직히. 하지만 나아가야 해. 왜냐하면 나의 삶을 살기 위해서
숨어 있던 내면의 자아를 밖으로 솔직하게 끌어 내기 위해서 말이지. 그 길을 걷는 것에 대해
또다른 시련과 후회가 찾아올지도 몰라. 하지만 이 경험을 통해 진정한 내 자신을 발견하고 새로운
인생의 이정표를 발견할 거라고 굳게 믿고 있어. 두려워하지마. 남들과 비교하지말고 오직 나의
내면의 목소리에 귀를 기울이고 그것에 집중해. 나를 믿고 또 나를 믿어.
나의 인생은 오로지 나의 것이니까.
Written by Simhyeon, Choe
Setting up Kernel mode debugging over a USB 2.0 Cable manually
우리는 커널 혹은 디바이스 드라이버를 개발하거나 디버깅할 때, 주로 VMWare나 Virtual Box 등의 가상 머신 툴로 많이 작업을 합니다만, 아무래도 그런 가상 머신 환경은 리얼 PC 환경에 비해 한계성을 가질 수 밖에 없습니다. 이를 테면, 리얼 PC 환경과 가상 환경 간의 차이로 구현이 달라져야 하거나 최신 호스트 인터페이스 컨트롤러를 기반으로 동작해야 하는 디바이스 드라이버의 경우, 벤더에서 가상 머신 기반의 개발 및 디버깅 가능하도록 지원해주기 전까지는 그 어떠한 작업도 불가능할 수 밖에 없지요. 만약 호스트 컴퓨터 두 대가 있다면 이를 USB 케이블로 연결하여 한 대는 호스트로, 또다른 한 대는 타깃으로 설정하여 리얼 환경에서 디버깅을 가능하도록 할 것입니다. 그래서 오늘은 PC 두 대를 USB 2.0 Cable로 연결하여 커널 모드로 디버깅하는 방법에 대해서 알아보도록 합시다.
※ Prerequisites:
호스트 컴퓨터(Host Computer) : "Debugger"를 실행한 컴퓨터
타깃 컴퓨터(Target Computer) : "Debuggee"로 실행된 컴퓨터 (디버깅 대상이 된 컴퓨터)
USB 2.0 Cable을 기반으로 디버깅을 지원하기 위해, 호스트 컴퓨터의 윈도우즈 운영체제는 Windows 2000부터 Windows 8까지 사용할 수 있으며, 타깃 컴퓨터는 Windows Vista, Windows 7이나 Windows 8 버전으로 실행되어야 합니다.
Debugging over a USB 2.0 cable requires the following hardware:
-
A USB 2.0 debug cable. This cable is not a standard USB 2.0 cable because it has an extra hardware component that makes it compatible with the USB2 Debug Device Functional Specification. You can find these cables with an Internet search for the term USB 2.0 debug cable.
-
The host computer must have a USB 2.0 controller that is compatible with the Enhanced Host Controller Interface (EHCI) specification.
-
The target computer must have a USB 2.0 controller that is compatible with the EHCI specification and that supports kernel debugging. Not all EHCI-compatible controllers have this support.
USB 2.0 Cable은 별도로 준비하셔야 합니다만, 구매를 희망하신다면 잘 알려진 Ajays USB 2.0 Host-to-Host Debug Device and Cable(http://www.semiconductorstore.com/Ajays-Technology/)을 추천드립니다. (Ajays USB 2.0 Host-to-Host Debug Device and cable 아래 그림 참조)
이 글에서는 Ajays Host-to-Host debug Device와 Cable을 사용하는 것으로 가정하고 설명을 드리도록 하겠습니다.

대부분의 메인보드에서 EHCI 기반의 USB 2.0 controller를 지원하기 때문에 특별히 신경쓰지 않아도 됩니다만, 이를 지원하지 않는다면 USB 2.0 Cable로 디버깅을 할 수 없다는 것을 유념하시기 바랍니다.
먼저 WinDbg 디버거가 설치되어 있지 않다면 Host PC에서 WinDbg 디버거 설치를 하셔야 합니다만, 이때 WinDbg 디버거 버전은 반드시 6.5.3.8 이상으로 설치하셔야 합니다. 아시다시피, WinDbg는 마이크로소프트사에서 무료로 배포하고 있으며, 일반적으로 WDK(Windows Driver Kit)에 함께 패키징되어 있습니다. WDK(7600 이상 버전)를 설치할 때, Debug Tool 관련 체크 박스에 클릭하시면 함께 설치할 수 있습니다.
1. Setting up the Target Computer
[Step 1] 타깃 컴퓨터에서 CMD.EXE를 마우스 우클릭으로 팝업된 윈도우에서 [관리자 권한으로 실행]을 선택합니다. 커맨드 프롬프트 윈도우에서 다음과 같이 타이핑합니다.
bcdedit /debug off
[Step 2] 타깃 컴퓨터를 재부팅합니다.
[Step 3] 타깃 컴퓨터에서 UsbView Tool을 실행시킵니다. (UsbView Tool은 호스트 컴퓨터에 설치된 "Debugging Tools for Windows package"에 포함되어 있음)
[Step 4] UsbView Tool로 두 가지 작업을 해야 합니다.
① Finding a physical USB connector
첫 번째는 EHCI와 호환되는 USB 2.0 Host Controller를 찾는 작업입니다. 커널 디버깅을 할 수 있는 물리적인 USB 커넥터를 찾기 위해, USB 2.0 Cable을 USB 소켓에 연결하였을 때 USB Debug Device가 어느 곳에 나타나는지 확인해야 합니다. 이를 갱신하도록 하려면 UsbView Tool에서 [Refresh]를 체크하면 됩니다. Usb Debug Device를 EHCI 기반의 Host Controller의 Port 1로 연결했다면, UsbView Tool의 TreeView에 "USB 2.0 Debug Connection Device"를 확인할 수 있습니다. 여전히 확인할 수 없다면 다른 USB 소켓을 바꿔가면서 반복적으로 연결하는 작업을 해서 확인해야 합니다. 이렇게 확인하였음에도 불구하고 보여지는 USB 커넥터를 발견할 수 없다면, 그것은 USB 커널 디버깅을 위한 타깃 컴퓨터로 사용이 불가능합니다. 이는 EHC 기반의 USB 커넥터를 메인보드에서 지원하지 않는다는 의미가 됩니다.
② Identifying Bus number, Device number and Function number
두 번째 작업은 해당 USB 2.0 Host Controller의 버스 번호, 디바이스 번호 그리고 펑션 번호를 찾는 작업을 해야합니다. UsbView의 Tree View에서 "USB 2.0 Debug Connection Device"가 표시된 자식 노드 상위의 USB Host Controller의 16진수값을 상기합니다. (아래 그림 빨간색 밑줄과 동그라미 확인)

그 후, [장치관리자]를 실행시켜서 해당 Host Controller의 노드를 찾습니다. 그리고 해당 노드의 속성 정보를 클릭하면 PCI 버스 번호, 장치 번호, 기능 번호를 확인할 수 있습니다. 이것 역시 상기해야 합니다.
[Step 5] 다시 CMD.EXE를 관리자 권한으로 실행하고 다음과 같이 입력합니다.
(Windows 7 기준)
bcdedit /debug on
bcdedit /debgsettings usb targetname:TargetName
bcdedit /set "{dbgsettings}" busparams x.y.z
다시 위의 커맨드들을 설명드리면,
/debug on은 해당 타깃 컴퓨터를 디버깅 프로세서로 동작시키기 위한 옵션입니다.
위의 TargetName은 USB Cable이 연결된 타깃컴퓨터 대상을 식별하기 위한 문자열 값입니다. 다시 말해서 디버깅 대상이 되는 여러 대의 타깃 컴퓨터가 있다면 호스트 컴퓨터는 그 중에서 특정 하나를 선택하고 디버깅해야 할 것입니다. 바로 이를 위해 존재하는 문자열을 의미합니다.
busparams x.y.z가 Step 4에서 상기했던 버스 번호, 장치 번호, 기능 번호를 의미합니다. 예를 들어, 버스 번호 0, 장치 번호 19, 기능 번호 4라면, busparams 0.19.4 처럼 입력합니다. 이때, busparams의 값은 Windows 7에서는 Decimal 값으로 입력해야 함을 유의합니다.
[Step 6] 다시 타깃 컴퓨터를 재부팅하고 BIOS Setup Utility로 들어가서 [Advanced] 탭의 Legacy USB Support를 [Disabled]로 설정합니다.

2. Setting up the Host Computer
[Step 1] USB 2.0 debug cable 양쪽을 호스트와 타깃 컴퓨터에 연결합니다. 당연히 조금 전에 언급했던 것 처럼, EHCI와 호환이 되는 USB 2.0 Host Controller와 반드시 연결해야 합니다.

USB Cable을 연결하면, USB Debug 드라이버가 자동적으로 설치될 수도 있고 안될 수도 있습니다. 만약에 장치관리자에서 확인하여 !로 표시된다면 수동적으로 드라이버를 설치해야 합니다. 그 절차는 아래와 같습니다.
a.[장치관리자]에서 USB 2.0 debug cable를 연결하였을 때 !로 나타나는 노드를 찾음
b.노드의 속성 페이지에서 드라이버 업데이트 혹은 인스톨을 선택
c.드라이버 설치 마법사에서 "Debugging Tools for Windows package"에 있는 usb2dbg.inf을
찾아서 설치
d.설치 마법사를 완료
[Step 2] 호스트 컴퓨터에서 첫 번째 USB Port를 찾습니다.
USB 버스를 통해서 디버깅을 수행하기 위해, Ajays device output port는 반드시 USB Port 1에 연결되어야 합니다(이는 호스트 컴퓨터에서만 해당하는 규칙임을 유의). 타깃 컴퓨터에서 UsbView를 사용해서 확인했던 것처럼, 마찬가지로 호스트 컴퓨터에서 USB Port 1를 찾기 위해, 순차적으로 Ajays Debug Cable을 연결해서 USB View에서 Refresh하여 확인하도록 합니다.
(아래 그림 참조. 이 그림에서는 Loc51이 USB Port 1에 해당함)

[Step 3] 호스트 컴퓨터에서 설치된 WinDbg를 실행하여 메인 메뉴에서 [File]-[Kernel Debug]를 선택합니다. 그리고 USB 2.0 탭을 선택하고 Target Name에 타깃 컴퓨터에서 입력했던 문자열 값을 동일하게 입력하고 OK 버튼을 클릭합니다.

WinDbg를 실행할 때마다 이렇게 작업하는 것이 번거롭다면, WinDbg.exe를 선택하고 우클릭해서 속성을 클릭하여 "대상"에 아래와 같이 입력합니다.
windbg.exe -b -k usb2:targetname=tagetname
이렇게 설정하면, WinDbg를 실행할 때마다 자동으로 지정된 Target Name으로 연결합니다.
3. 호스트 컴퓨터와 타깃 컴퓨터의 디버깅 연결
위의 모든 과정에서 설명드렸던 설정을 완료하셨다면, 호스트 컴퓨터에 설치된 WinDbg를 실행합니다. 그러고나서 타깃 컴퓨터를 재부팅합니다. 성공적으로 타깃 컴퓨터가 연결되었다면 아래의 그림과 같이 출력될 것입니다. 여기서 [Ctrl] + [Break]키를 누르면 소프트웨어 브레이크 포인트가 설정되고 타깃 컴퓨터는 HALT 상태로 대기하게 됩니다.

[Notes and References]
http://msdn.microsoft.com/en-us/library/windows/hardware/ff556869(v=vs.85).aspx
http://www.apriorit.com/our-company/dev-blog/210-win-debug-with-usb
http://blogs.msdn.com/b/usbcoreblog/archive/2010/10/25/setting-up-kernel-debugging-with-usb-2-0.aspx
그럼 여기까지 마무리하도록 하겠습니다. 좋은 주말 보내세요.
Written by Simhyeon, Choe
SMP(Symmetric Multi-Processing) vs. AMP(Asymmetric Multi-Processing)
오늘은 SMP와 AMP에 대해 간략히 학습하는 시간을 갖도록 하겠습니다.
1. SMP(Symmetric Multi-Processing)
SMP은 두 개 이상의 동일한 프로세서가 하나의 메모리, I/O 디바이스, 인터럽트 등의 자원을 공유하여 단일 시스템 버스를 통해, 각각의 프로세서는 다른 프로그램를 실행하고 다른 데이터를 처리하는 시스템을 의미합니다. 달리 얘기하면, 두 개 이상의 프로세서가 하나의 컴퓨터 시스템 아키텍쳐를 공유하도록 연결되어 있으며, 각각의 프로세서는 독립적으로 자신의 작업을 처리한다는 의미가 됩니다. 아래의 그림에서 SMP 시스템을 봅시다.

그래서 SMP는 두 개 이상의 프로세서가 하나의 메인 메모리와 버스를 공유하도록 설계된 하드웨어와 이를 운용하기 위한 소프트웨어 아키텍쳐와 관련이 있습니다. 두 개 이상의 프로세서는 동일한 버스 아키텍쳐를 통해 시스템의 모든 I/O 디바이스에 대한 접근이 가능하며, 이는 적절한 운영체제 정책 디자인(프로세스 스케줄링과 인터럽트 로드 밸런싱 등)에 따라서 운용되어야 합니다. SMP에서 모든 프로세서들은 동일한 기능과 역할을 가지고 작업을 수행합니다. 이를 테면, 모든 프로세서는 운영체제 코드를 실행하고 I/O 오퍼레이션을 담당할 수 있습니다. 오늘날의 대부분의 멀티프로세서 시스템은 SMP 아키텍쳐를 사용합니다. Intel x86 역시 마찬가지로 SMP 아키텍쳐를 채택하고 있습니다. 일반적으로 SMP 시스템 기반에서 보다 빠른 메모리 맵 데이터 엑세스와 시스템 버스 트래픽을 최소화하기 위해, 각각의 프로세서마다 캐쉬 메모리를 가지고 있습니다.
2. AMP(Asymmetric Multi-Processing)
AMP는 두 개 이상의 각각의 프로세서가 자신만의 다른 특정 기능을 수행하는 아키텍쳐를 의미합니다. 예를 들어, 하나의 프로세서가 메인 운영체제를 실행하도록 하고 다른 프로세서는 I/O 오퍼레이션 기능을 전용으로 수행하는 형태의 아키텍쳐로 존재할 수 있습니다. 이때, 두 개의 프로세서는 메인 메모리에서 자신의 커널 이미지를 실행하고 주소 공간 역시 분리되어 있는 컨셉이라고 볼 수 있지요. 여기서 커널 이미지는 동일하거나 서로 다른 것으로 사용될 수 있습니다.
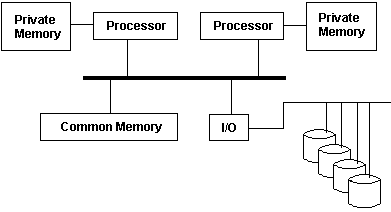
[Asymmetric Multiprocessing Example I]
This configuration has multiple memory units with some of those not shared by all processors
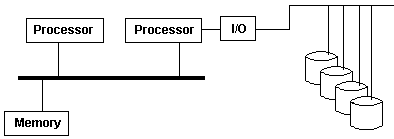
[Asymmetric Multiprocessing Example II]
This configuration has one processor doing all I/O.
3. Summary AMP vs. SMP
An AMP system:
• multiple CPUs
• each of which may be a different architecture [but can be the same]
• each has its own address space
• each may or may not run an OS [and the OSes need not be the same]
• some kind of communication facility between the CPUs is provided
An SMP system:
• multiple CPUs
• each of which has the same architecture
• CPUs share memory space [or, at least, some of it]
• normally an OS is used and this is a single instance that runs on all the CPUs,
dividing work between them
• some kind of communication facility between the CPUs is provided
[and this is normally shared memory]
[Notes and References]
http://en.wikipedia.org/wiki/Symmetric_multiprocessing
http://en.wikipedia.org/wiki/Asymmetric_multiprocessing
http://ohlandl.ipv7.net/CPU/ASMP_SMP.html
http://blogs.mentor.com/colinwalls/blog/2010/06/07/amp-vs-smp/
오늘은 여기까지만 간단히 마무리하겠습니다. 좋은 하루 보내세요.
Written by Simhyeon, Choe
지난 시간에 이어, x86 메모리 관리 스킴에서 나오는 중요한 용어들을 정리해 봅시다.
1) 세그먼트 레지스터(Segment Register)
인텔 문서에서 설명한 내용을 그대로 번역해보면, 어드레스 변환과 코딩 복잡도를 최소화하기 위해, 프로세서가 최대 6개의 세그먼트 셀렉터 값을 유지하기 위한 레지스터 셋(CS, DS, ES, FS, GS, SS)이라고 나와 있습니다. 세그먼트 레지스터와 세그먼트 유닛(세그먼테이션을 처리해주는 하드웨어)이 존재하기 때문에 우리는 특정 세그먼트 영역의 참조를 위해 어떤 범용 레지스터나 스택 영역에 참조할 세그먼트 셀렉터 값을 가져와서 어드레스 변환 작업을 일일이 직접 구현할 필요가 없습니다.

모든 세그먼트 레지스터는 Visible 영역과 Hidden 영역을 가지고 있습니다. 사실, 유저 관점에서는 Visible 영역에 대해서만 관심을 가져도 문제가 없습니다. 유저 관점에서 접근 가능한 레지스터 영역은 오로지 16비트 셀렉터를 저장하기 위한 영역만 존재합니다. Hidden 영역에 대해서 간단히 설명을 드리자면, 이것은 프로세서가 디스크립터를 미리 캐쉬하기 위한 영역으로 사용됩니다. 인텔 메뉴얼(System Programming Guide Vol.3-11)에 언급되어 있듯이, 세그먼트 디스크립터로부터 베이스 어드레스와 리미트 어드레스 읽기 위해, 여분의 버스 사이클 레이턴시없이 프로세서가 바로 어드레스 변환할 수 있습니다.
2) 세그먼트 셀렉터(Segment Selector)와 세그먼트 디스크립터(Segment Descriptor)
세그먼트 셀렉터는 하나의 세그먼트 디스크립터를 지시하기 위한 16비트 구조체입니다. 이 16비트 구조체는 아래와 같은 필드 구조체로 이루어져 있습니다.

여기서 용어 정리를 확실히 짚고 넘어가야 할 부분이 있습니다만, 세그먼트 레지스터를 세그먼트 셀렉터와 동일한 것처럼 이해하실 수 있습니다. 사실 엄밀히 말하면 세그먼트 레지스터와 세그먼트 셀렉터는 같다고 정의할 수 없습니다. 세그먼트 셀렉터는 위에서 말씀드린 것처럼, 세그먼트의 정보가지고 있는 디스크립터를 식별하기 위한 값이며, 세그먼트 레지스터는 실제 물리적인 레지스터입니다. 다만, 주요 커널 관련 서적에서 이를 동일하게 취급하는 이유가 보호 모드에서는 세그먼트 레지스터가 항상 세그먼트 셀렉터 값을 저장하기 위한 용도로 사용되기 때문입니다.
그렇다면 세그먼트 셀렉터가 필요한 이유가 무엇일까요? 이유는 간단합니다. 세그먼트 셀럭터 값을 저장하기 위한 세그먼트 레지스터는 16비트 레지스터 셋인데, 보호 모드에서 모든 세그먼트는 32비트 선형 주소 공간에서 위치할 수 있습니다. 그리고 한 세그먼트 영역의 시작과 끝에 대한 주소 정보도 필요할 것이고 또한 각각의 세그먼트는 서로 다른 보호 속성을 가질 수 있습니다. 유저 레벨에서 접근이 가능한 세그먼트 영역인지 아니면 오로지 커널 레벨에서만 접근이 가능한 영역인지 혹은 오직 읽기만 가능한 영역이 있는가하면, 읽기/쓰기 모두 허용하는 등의 속성들을 의미합니다. 16비트 세그먼트 레지스터로 32비트 선형 주소 공간을 모두 표현할 수 없을 뿐만 아니라, 그런 속성 정보들 역시 표현할 수가 없습니다. 이 때문에 각 세그먼트마다 여러가지 속성 정보를 가지고 있는 별도의 구조체가 필요합니다만, 그것이 세그먼트 디스크립터(Segment Descriptor)입니다. 이 구조체의 크기는 총 64비트로 구성되어 있으며, 아래와 같이 주소 정보 및 여러가지 속성 필드들로 구성되어 있습니다.

그렇다면 이번에는 16비트 세그먼트 레지스터에 64비트 세그먼트 디스크립터 정보를 담을 수 있을까요? 역시 불가능합니다만, 이쯤되면 다들 아시겠지요. 바로 하나의 세그먼트 디스크립터를 가리키기 위한 용도로 16비트 세그먼트 셀렉터 값을 참조한다는 사실을 말입니다. 16비트 세그먼트 셀렉터 정보를 보면 세그먼트 디스크립터의 인덱스 값을 가지고 있습니다. 그 인덱스 값으로 특정 세그먼트 디스크립터를 찾아갈 수가 있지요.
3) 세그먼트 디스크립터 테이블(Segment Descriptor Table)
이것은 두 개 이상 세그먼트 디스크립터들의 집합입니다. 방금전에 제가 세그먼트 디스크립터는 여러가지 속성 필드를 가지고 있는 구조체라고 언급드렸습니다. 그런 구조체를 연속적으로 여러 개를 가지고 있는 구조체 배열이 세그먼트 디스크립터 테이블입니다.

4) 주소 개념 설명
- 논리적인 주소(Logical Address)
세그먼트 + 오프셋(DS:[0x1000]) 조합으로 표현된 주소를 의미합니다.
- 선형 주소(Linear Address)
세그먼트 + 오프셋 조합의 논리적인 주소로 세그먼테이션을 통해, 특정 세그먼트 디스크립터의 베이스 주소와 오프셋을 합친 주소값입니다.
- 물리 주소(Physical Address)
실제 물리 메모리 주소를 의미합니다.
- 가상 주소(Virtual Address)
페이징 스킴을 지원할 때 선형 주소가 가상 주소가 됩니다.
보호 모드에서 선형 주소는 페이징 스킴의 지원 여부에 따라 개념이 물리 주소를 의미하거나 가상 주소를 의미할 수 있습니다. 아래의 표를 참조하시면 쉽게 구분할 수 있습니다.

여기까지 마무리하고 다음 시간에는 세그먼트 관련 속성 필드에 대해 알아보도록 하겠습니다.
좋은 밤 보내세요.
Written by Simhyeon, Choe
I had small talk with junior in university by messenger after all these years. She has taken a gloomy view about herself and her career path. I felt as if she stopped intellectual and spiritual growth since I have known her for seven years. Also, She was no longer bouncy and passinate as she was student in university. I tried to make her think positively, but on the contrary she gave me thoughtless advice. She said that you should have the detailed plan to achieve your dream and then she quoted Allyson Felix's saying. What she said was both funny and shocking. At that moment, I really wanted to say her that Acknowledging yourself is what's important in life, but I didn't say her anything. Actually, I took this to be ironical, because she said to me that I don't have any dream. I thought she was really pathetic.
Written by Simhyeon, Choe
지난 시간에 이어 메모리 세그먼테이션에 대해서 자세히 알아봅시다.
세그먼테이션은 x86 아키텍쳐에서 제공하는 메모리 관리 스킴 중에 하나로써, 메인 메모리 영역을 세그먼트라는 단위로 분할하여 관리합니다. 세그먼테이션을 수행한다는 의미는 하나의 세그먼트 영역의 베이스 어드레스와 오프셋으로 어떤 특정 메모리 위치를 참조하는 동작을 의미합니다. 이런 뻔한 설명을 드려도 세그먼테이션 개념이 와닿지 않는 핵심적인 의문 두가지가 있습니다. 세그먼테이션을 수행하는 주체는 무엇인가? 그리고 세그먼테이션은 언제 수행되는가? 우선 우리는 이 질문에 대답을 해보도록 합시다.
아래의 간단한 C언어 코드로 예를 들겠습니다.
unsigned int gValue; // 데이터 세그먼트 오프셋 0x1000에 전역 변수 gValue가 위치한다고 가정
int main(void)
{
gValue = 0x0000FFFF; // 0x0000FFFF 값을 전역 변수 gValue에 대입
return 0;
}
자, 이번에는 위의 C언어 코드를 CPU가 해석할 수 있도록 컴파일해서 저 간단한 프로그램을 실행했다고 가정하겠습니다. (사실, 의미없는 동작이기 때문에 컴파일러가 이를 최적화하지만 그냥 무시합시다)
그러면 메모리에 로딩된 프로그램은 대략적으로 아래의 어셈블리 코드로 동작할 것입니다.
0x4005000 MOV EAX, 0x0000FFFF
0x4005004 MOV DWORD PTR DS:[0x1000], EAX
1) 프로그램 카운터 0x4005000에서 명령어 MOV EAX, 0x0000FFFF을 패치하고 수행
- EAX 레지스터에 즉치값 0x0000FFFF 대입
2) 프로그램 카운터 0x4005004에서 명령어 MOV DWORD PTR DS:[0x1000], EAX를 패치하고 수행
- 데이터 세그먼트 베이스 어드레스로부터 오프셋 0x1000 위치에서 4바이트만큼 참조하여
0x0000FFFF을 쓰기

[그림1] CPU가 명령어를 실행할 때, 오퍼랜드에 기술된 메모리 위치를 참조하는 과정
세그먼테이션 동작을 전적으로 수행하는 주체는 CPU가 되고, 세그먼테이션을 수행하는 시점은 CPU가 하나의 명령어를 패치, 디코딩 후 오퍼랜드의 주소를 지정하기 위해 계산하는 시점입니다. 이때, 명령어 셋에 명시된 어드레싱 모드가 Immediate Addressing이 아닌 Direct Addressing, Register Indirect Addressing, 그리고 Base Addressing 등에 해당한다면 보호 모드(Protected Mode)에서는 세그먼트 어드레싱(Segmented Addressing) 즉, 세그먼테이션을 수행하게 됩니다. 여기선 세그먼테이션을 수행하는 시점을 알게 되었습니다만, 그 구체적인 과정에 대해서는 여전히 언급하지 않았습니다. 다음에는 위의 그림에 나오는 세그먼테이션 과정을 설명하기 앞서, 몇 가지 이해가 필요한 개념들의 정의를 짚고 넘어 가도록 합시다.
Notes and References
------------------------------------------------------------------------------------------------------
1. http://cs.smith.edu/~thiebaut/ArtOfAssembly/CH03/CH03-3.html (Instruction Execution)
2. http://en.wikipedia.org/wiki/X86#Addressing_modes (Addressing Modes)
3. http://forum.osdev.org/viewtopic.php?f=11&t=26012&start=0 (To load a segment register, CPU operation)
4. http://www.supernovah.com/Tutorials/Assembly3.php (Addressing Modes)
5. IA-32 Intel Architecture Manual VOLUME 2A: Instruction Set Reference, A-M (Instruction Set Architecture)
------------------------------------------------------------------------------------------------------
오늘은 시간이 늦었으니, 짧게 마무리하고 여기서 다시 추가로 계속 설명드리도록 하겠습니다.
편안한 밤 보내세요.
Written by Simhyeon, Choe
지난 시간에 이어, x86 아키텍쳐 메모리 관리 스킴에 대해서 계속 공부하도록 합시다. 지난 시간에는 세그먼테이션과 페이징의 기본 개념과 필요성에 대해서 언급하였는데요. 현재의 메모리 관리 스킴을 설명하기 앞서, 일단 과거 x86 아키텍쳐의 메모리 관리 스킴의 히스토리를 조금 짚고 넘어가도록 하겠습니다.
1) 세그먼트(Segment)와 오프셋(Offset)
세그먼테이션은 고유한 속성을 가진 메모리의 조각을 영역별로 나누어 어드레싱하고 관리하는 기법이라고 이전 챕터에서 정의하였습니다. 과거 8086 아키텍쳐에서 지원하는 세그먼테이션의 경우에는 현재 세그먼테이션 스킴과 비교해 컨셉이 전혀 달랐습니다. 8086 아키텍쳐에서 사용한 세그먼테이션의 근본적인 배경은 더 많은 메모리 주소 공간을 어드레싱하기 위함이었지요. 당시 8086 아키텍쳐는 8개의 16비트 레지스터와 16비트 데이터 버스와 20비트 어드레스 버스를 가졌습니다. 하나의 16비트 레지스터로 20비트 어드레스를 표현할 수 없었기 때문에 인텔이 고안해낸 방법은 세그먼트:오프셋 조합으로 20비트 어드레스를 나타내는 것이었습니다. 그러니까 세그먼트 값을 4비트만큼 왼쪽으로 쉬프트하고 여기에 오프셋 값을 더하여 온전한 20비트의 물리 주소를 표현하였습니다.

이와 같이, 세그먼트:오프셋 조합으로 물리 주소를 표현하면 동일한 물리 주소를 다양한 세그먼트:오프셋 조합으로 표현할 수 있습니다. (예를 들면, 0xFFFFF 물리 주소는 FFFFh:000Fh, FFF0h:00FFh, FF00h:0FFFh, F000h:FFFFh로 표현 가능) 그렇다면 만약에 FFFFh:0010h으로 물리 주소를 표현하면 어떻게 될까요? 이 경우엔 20비트로 표현할 수 있는 범위를 초과하기 때문에 다시 0x0000의 물리 주소로 랩핑됩니다.
2) 리얼 모드(Real Mode or Real Address Mode)와 보호 모드(Protected Mode)
8086 머신에서는 20비트 어드레스를 표현하기 위해 세그먼트:오프셋 조합으로 주소 지정을 하게 되는데, 1MB 범위의 메모리 영역 어느 곳이든 주소 지정이 가능할 뿐만아니라, 읽기/쓰기가 가능합니다. 즉, 전적으로 프로그램을 구현하는 프로그래머가 메모리 관리를 책임져야 하며, 이는 과거 머신에서 메모리 관리에 대한 안정성과 보안성에 대한 고려가 되지 않았습니다. 이러한 CPU 연산 모드를 리얼 모드라고 합니다. 8086 이후에 등장하게 된 80286 프로세서부터 멀티 태스킹 환경을 제공했습니다. 그리고 어드레스 버스가 24비트로 확장되었으며, 더이상 이전의 세그먼트:오프셋 조합으로 주소 지정하지 않고 세그먼트 셀렉터가 가리키는 세그먼트 디스크립터의 베이스 어드레스와 오프셋의 조합으로 최대 16MB까지 주소 지정을 가능하도록 하였습니다. 이것은 제가 원래 처음에 설명드렸던 세그먼테이션 컨셉이기도 합니다. 하위 호환성 유지를 위해 여전히 리얼 모드를 제공하였고 새롭게 보호 모드를 도입하였습니다. 이것은 다른 세그먼트들간의 코드, 데이터, 스택 영역에 대한 오버랩핑을 제한하도록 하고 세그먼트마다 특권 레벨을 부여하여 합법적이지 않은 접근에 대해 각 세그먼트 영역을 보호하였습니다. 80286 다음으로 등장하게 된 프로세서가 80386으로, 이때부터 완전한 32비트 레지스터 셋과 함께 32비트 버스 라인을 가졌습니다. 여기서부터 유저 영역과 커널 영역의 주소 공간을 나누어 유저 레벨에서 동작하는 프로그램이 커널 영역의 접근을 보호하도록 하였습니다. 그리고 유저 레벨의 프로세스마다 독립적인 영역으로 분리를 통해, 서로간의 메모리 영역 침범을 제한하여 안정성과 보안성을 높였습니다. 그리고 페이징 유닛의 추가로, 유저 프로세스마다 4GB에 이르는 주소 공간에 가상 메모리를 할당할 수 있도록 지원하였습니다.
여기까지 정리를 마무리하도록 하겠습니다. 즐거운 하루 보내세요.
Written by Simhyeon, Choe
이번 시간에는 x86 아키텍쳐의 메모리 관리 스킴에 대해서 알아 보도록 합시다.
사실, 이 주제를 포스팅하는 것에 대해 고민하였습니다. 이 주제로 검색하면 굉장히 잘 정리된 블로그나 기술 문서들이 많기 때문입니다. 특히, 운영체제 개발 관련 서적에서는 이와 관련된 내용이 체계적으로 잘 정리가 되어 있습니다. 그리고 그것을 구현한 코드도 함께 볼 수 있구요. 이미 보편적으로 오래전에 파급된 이 주제를 제가 이제와서 언급하는게 적절한지는 잘 모르겠군요. 제가 x86 Architecture에 대해 공부한지는 꽤 되었습니다. 예전에 차라리 정리를 해놓았으면 하는 후회가 남네요. 뒤늦게라도 다시 정리를 해보는 것도 리마인드 차원에서 나쁘지는 않을 것 같군요. 사실 저는 개발하는 것보다 이론 공부를 더 좋아하는 성격인지라, 순전히 이론만으로 이 주제를 잘 설명할지는 의문이긴 합니다만, 이번 시간에 한 번 정리를 해보도록 하겠습니다.
당연히 이 주제는 너무나도 유명한 아래의 인텔 메뉴얼을 참고하였습니다.
Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3A:
System Programming Guide, Part 1
x86 아키텍쳐에서 메모리 관리 기법은 크게 세그먼테이션과 페이징으로 분류할 수 있습니다. 이 두가지 메모리 관리 기법을 언급드리기 앞서, 우리가 선행해야 할 것은 과거의 메모리 관리 스킴입니다. 과거 메모리 관리 스킴으로 시작하여 현재 어떻게 변천해 왔는지 알아보는 것은 충분히 의미가 있습니다.
우선, 세그먼테이션(Segmentation)를 간단히 정의해도록 합시다. 세그먼트는 우리말로 풀어보면 사전적 의미는 '조각'이고, 세그먼테이션은 '분할'로 나오네요. 굳이 억지로 번역하면 '조각 나누기' 정도로 해석할 수 있겠네요. 그럼 필요한 이유가 뭘까요? 저의 생각으로는 적당히 세 가지 정도를 이유로 들 수 있을 것 같은데요. 첫 번째는 코드와 데이터처럼, 서로 다른 성격을 지닌 메모리 영역을 나누어 관리하기 위함입니다. 당연한 얘기가 되겠지만 프로그램을 동작중에 데이터를 코드 영역에다가 쓰기 행위는 제한되어야 할 것이고, 또 다른 예로는 프로그램 특성상 오직 읽어야 하는 영역임에도 불구하고 이를 접근하여 쓰기를 시도하는 행위도 읽기 전용 메모리 속성으로 구분되어야 할 것입니다. 이와 같이, 세그먼테이션을 통해 각 세그먼트의 보호 속성을 지정하여 관리할 수 있습니다. 두 번째는 필요에 따라서 특정 메모리 영역을 공유할 수 있습니다. 동일한 프로그램을 두 번 실행되었다고 하더라도 프로그램 코드를 두 번 메모리에 로딩할 필요없이 특정 코드 세그먼트 영역에 한 번만 로드하여 공유하고 데이터 영역만 분리하여 효율적인 메모리 관리를 할 수 있습니다. 이것은 사실 멀티 태스킹 환경에서 그러한 지원은 당연하다고 볼 수 있지요. 세 번째 이유는 특정 메모리 영역의 접근이 용이하다는 점입니다. 단순히 물리 메모리를 하나로 코드와 데이터 등의 영역을 관리한다면 유저 입장에서는 특정 영역에 접근할 때, 예를 들어 코드는 0xFFFF, 메모리는 0x1000와 같은 절대 위치를 항상 참조해야 하기 때문에 번거로움이 있습니다. 그래서 각 세그먼트 영역마다 베이스 주소와 한계 주소과 같은 정보를 CPU에게 미리 알려 준 상태라면 유저(프로그래머) 관점에서는 어떤 영역이든 오프셋 0을 기준으로 하여 접근하면 되니 메모리 관리에 신경쓰지 않아도 될 것입니다. 다시 요약하면, 속성이 다른 영역의 메모리를 적절히 나누어 관리하기 위한 기법으로 정의할 수 있습니다. 그렇다면 이번에는 페이징에 대한 정의를 찾아봐야 할 것 같습니다만, 앞서 페이징이 필요한 이유부터 알아봅시다.

우선 세그먼테이션을 기반으로 하여 가상 메모리가 아닌 순수 물리 메모리상에서 여러 개의 프로그램이 동작하는 멀티 태스킹 환경이라고 가정하겠습니다. 그림①은 프로그램 크기가 다른 프로세스 A, B, C, D, E가 차례대로 물리 메모리 영역에 로딩된 상황입니다. 순서대로 실행하여 메모리에 로딩한 상황 자체는 특별한 문제가 없습니다. 그리고 그림②에서는 프로세스 B와 D가 실행이 끝나고 언로딩된 상황을 보여주고 있습니다. 여기서 문제는 다시 새로운 프로세스 F를 실행하기 위해 로딩하려는 시점입니다. 그림에서 보시다시피, ⓐ와 ⓑ 영역에 Process F를 연속된 공간으로 로딩하기엔 공간이 부족합니다. 이와 같이, ⓐ와 ⓑ 영역을 메모리에서 외부 단편화(External Fragmentation)가 발생하였다고 표현합니다. 외부 단편화의 범위는 프로세스가 가지고 있는 코드와 데이터 영역 모두가 됩니다. 이런 외부 단편화로 인해, 프로그램 로딩을 위한 적절한 공간을 할당받을 수 없다면 기존에 로딩한 프로그램들을 재배치하고 조각으로 나누어진 영역들을 하나로 합치는 등의 워스트 케이스가 발생하면 그 버든은 아주 클 수 밖에 없지요. 바꿔 얘기하면, 외부 단편화 문제는 세그먼테이션에서 발생하는 문제라고 말씀드릴 수 있습니다. 외부 단편화 문제를 해결하기 위해, 인텔 x86에서는 페이징 기법을 제공합니다. 프로그램을 실행할 때 코드와 데이터를 통째로 로딩하는 것이 아니라, 모든 영역을 페이지 단위(IA-32에서는 기본 4K)로 나누어 메모리를 관리할 수 있습니다.

위의 왼쪽 그림을 보면, 물리 메모리에서 각 프로세스의 코드와 데이터 일부가 페이지 단위로 로드되어 있습니다. 중간 그림에서 프로세스 D의 실행이 종료되고 페이지 아웃된 후에 새로운 프로세스 E 코드 일부가 물리 메모리에 로드된 것을 보여주고 있습니다. 페이지 단위의 메모리 공간 확보만 보장된다면 프로그램 영역 할당은 쉽게 이루어질 수 있습니다. 즉, 페이징 기법으로 외부 단편화 문제를 극복할 수 있습니다. 그리고 여기서 아직 가상 메모리 개념을 자세히 설명드리지 않았습니다만, 사실 페이징 기법은 가상 메모리 스킴과 밀접한 관련이 있습니다. 위의 그림에서는 단지 실행에 필요한 프로세스 코드와 데이터 일부가 로드된 것을 보여준다는 점을 유념하시기 바랍니다. 일단, 오늘은 여기까지만 정리하고 다음편에서 이 주제에 대해서 계속 설명드리겠습니다. 좋은 하루 보내세요.
Written by Simhyeon, Choe
오늘은 디바이스와 드라이버 레이어에 대해 공부해 봅시다.
Windows Driver Model(이하 WDM)은 아래 그림과 같이 드라이버 레이어를 표현하고 있습니다.

일반적으로 디바이스 오브젝트의 스택은 위의 그림처럼 표현합니다. (디바이스에 따라 디바이스 스택은 위의 그림보다 계층이 적을 수도 혹은 보다 많을 수도 있음을 유의하셔야 합니다) 우선 디바이스 오브젝트를 정의하자면, 이것은 소프트웨어가 하드웨어를 관리하기 위해 시스템이 생성한 데이터 스트럭쳐라고 할 수 있습니다. 하나의 디바이스 오브젝트는 I/O REQUEST를 처리하기 위한 논리적, 가상 혹은 물리적인 디바이스를 의미합니다. 전혀 관련이 없는 다른 개념이지만 좀 더 이해를 돕고자 비유한다면, 우리는 객체 지향에서 어떤 기능과 속성을 포함하는 클래스라는 용어를 알고 있습니다. 그리고 클래스로 각기 다른 속성값을 가지고 있는 메모리에 존재하는 객체나 인스턴스로 생성하여 이를 표현합니다. 이 비유에서 클래스는 논리적인 디바이스, 가상의 디바이스나 물리적인 디바이스를 의미합니다. 그리고 객체는 디바이스의 고유의 속성을 표현하기 위한 디바이스 오브젝트로 비유할 수 있습니다. 이 개념 비유는 절대적인 비유라고 할 수 없으며, 단지 이해를 돕기 위해서 이렇게 설명을 드립니다. 그래서 물리적인 디바이스 하나를 위해, 많은 디바이스 오브젝트가 존재할 수 있습니다. 디바이스 스택에서 가장 낮은 레벨의 디바이스 오브젝트는 PDO(Physical Device Object)라고 하며, 디바이스 스택에서 중간 계층 레벨에 존재하는 디바이스 오브젝트는 FDO(Functional Device Object)라고 합니다. 그리고 위의 그림에서 보이는 것과 같이, FDO의 위와 아래에는 하나 이상의 FiDO(Filter Device Object)가 위치할 수도 있습니다. 통상 FDO 위에 위치한 Filter Device Object는 Upper filter라고 하며, FDO와 PDO 사이에 위치한 Filter Device Object는 Lower filter라고 정의합니다.
그렇다면 디바이스 스택은 언제 구성하게 될까요? 간략히 순서를 설명하면, 시스템을 부팅하는 동안 버스 드라이버는 버스에 연결된 디바이스를 열거하고 각 디바이스들의 PDO를 생성합니다. 그리고 PnP Manager는 버스 드라이버가 생성한 PDO list를 참조하여 각 드라이버의 엔트리 포인트인 DriverEntry를 호출하여 콜백 루틴을 초기화하고 AddDevice로 디바이스를 위한 FDO를 생성하고 이를 디바이스 스택에 추가합니다. 물론, 여전히 PDO와 FDO 개념에 대한 감이 오지 않을 것이라고 생각합니다. 한 가지 예를 들어 보도록 하겠습니다. 컴퓨터에 연결된 키보드 하나가 연결되어 가정합시다. 키보드는 흔히 우리가 잘 알고 있는 디바이스입니다. 당연히 키보드의 입출력을 처리하기 위한 키보드 디바이스 드라이버가 필요할 것입니다. 위에서 부팅 과정 중에 버스 드라이버가 모든 디바이스들을 열거한다고 하였습니다. 당연히 키보드도 디바이스기 때문에 열거가 되겠지요. 여기서 버스 드라이버가 인식한 키보드 장치를 관리하기 위해 생성한 객체가 바로 PDO(Physical Device Object)가 됩니다. 자, 그럼 생성하고 나서 키보드가 동작을 해야되겠죠? 이에 키보드 드라이버는 키보드 기능 동작에 관한 세부적인 설명을 기술한 FDO(Functional Device Object)를 생성합니다.
위에서 언급한 것처럼, 버스 드라이버가 디바이스의 PDO를 생성하고 해당 디바이스의 드라이버에서 구체적으로 기능적인 역할을 위해 FDO를 생성한다고 하였습니다. 그 이후의 동작 과정을 살펴보면, PnP Manager가 버스 드라이버에 의해 생성된 PDO List를 참조하여 디바이스 스택의 중간 계층에 위치한 Filter와 Function 드라이버를 찾기 위해 레지스트리 데이터 베이스를 조사합니다. 여기서 레지스트리 데이터 베이스는 디바이스 드라이버에 대한 여러가지 정보를 가지고 있는데, 특정 레지스트리 엔트리에서 디바이스 스택상에 순서대로 스택을 구성할 드라이버를 정의하고 있습니다. 그다음 PnP Manager는 가장 낮은 레벨의 Filter Driver를 로딩하고 Object를 생성하고나서 AddDevice Function을 호출합니다. 그리고 여기에서 FiDO(Filter Device Object)를 생성하고 이를 PDO와 연결하는 작업을 합니다. 마찬가지로 PnP Manager는 현재 구성중인 디바이스 스택에서 로딩하고 호출할 하위 Filter Driver, Function Driver, 상위 Fiter Driver의 Object를 각각 생성하고 차례대로 아래에서부터 서로 연결하여 디바이스 스택을 구성합니다. 결과적으로 위의 그림과 같이 디바이스 스택이 형성됩니다.
(참조 : http://www-user.tu-chemnitz.de/~heha/oney_wdm/ch02b.htm)
시간이 늦었으니, 오늘은 간단히 여기까지만 정리하도록 하겠습니다.
Written by Simhyeon, Choe
 Prev
Prev

 Rss Feed
Rss Feed
{kind=link}